AWS (Amazon Web Services) S3 Multipart Upload ist eine Funktion, die es ermöglicht, große Objekte (Dateien) in kleineren Teilen oder „Chunks“ auf Amazon Simple Storage Service (S3) hochzuladen und diese dann serverseitig zu einem vollständigen Objekt zusammenzusetzen.
Dieser Prozess bietet mehrere Vorteile gegenüber herkömmlichen einzelnen Uploads:
Um einen mehrteiligen Upload zu starten, müssen wir eine neue mehrteilige Upload-Anfrage mit der S3-API erstellen und dann einzelne Teile des Objekts in separaten API-Aufrufen hochladen, die jeweils durch eine eindeutige Teilenummer identifiziert werden.
Sobald alle Teile hochgeladen sind, ist der mehrteilige Upload abgeschlossen und S3 fügt die Teile zum endgültigen Objekt zusammen. Außerdem können Sie einen mehrteiligen Upload jederzeit abbrechen, um hochgeladene Teile zu bereinigen und Speicherkosten zu sparen.
Mehrteilige Uploads werden häufig verwendet, wenn es sich um Dateien handelt, die in der Regel größer als 100 MB sind, oder wenn während des Upload-Vorgangs instabile Netzwerkbedingungen zu erwarten sind.
In diesem Artikel sollen die Vorteile von AWS S3-Multipart-Uploads, detailliert und praktisch veranschaulicht werden, indem eine Implementierung mit Dropzone.js und dem Python-Framework Flask zusammen mit dem AWS S3 boto3 Python SDK bereitgestellt wird.
Aus Sicherheitsgründen werden die Anfragen an S3 über eine Flask-REST-API weitergeleitet. Beginnen wir mit der Erstellung und Einrichtung der Flask-App:
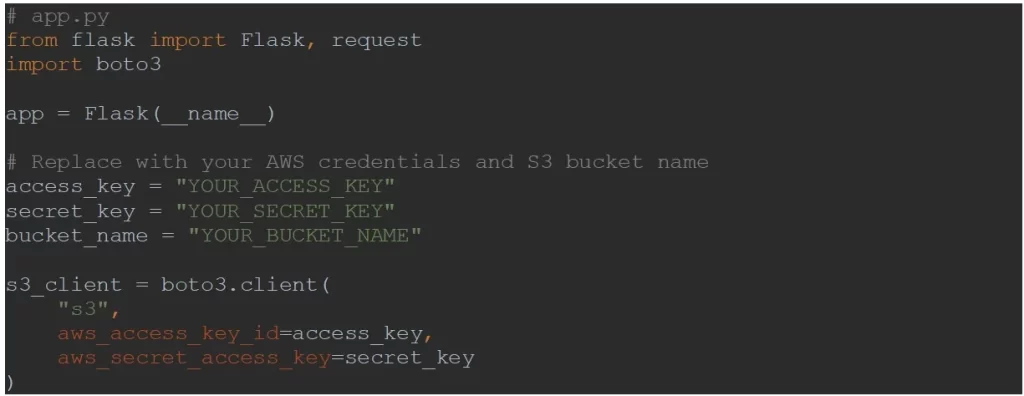
Als Nächstes erstellen wir drei Flask-Endpunkte für die folgenden Funktionen:
Die unten aufgeführte Endpunktimplementierung startet einen mehrteiligen Upload in den angegebenen S3-Bucket und Objektschlüssel unter Verwendung des Boto3 SDK.
Die Funktion „create_multipart_upload“ wird aufgerufen, um einen neuen mehrteiligen Upload zu erstellen, und die von der API zurückgegebene „UploadId“ ist in der Antwort enthalten.
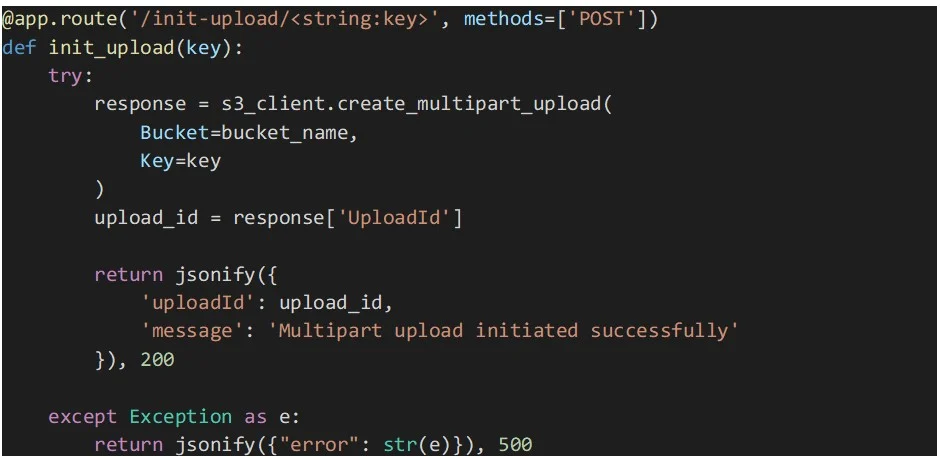
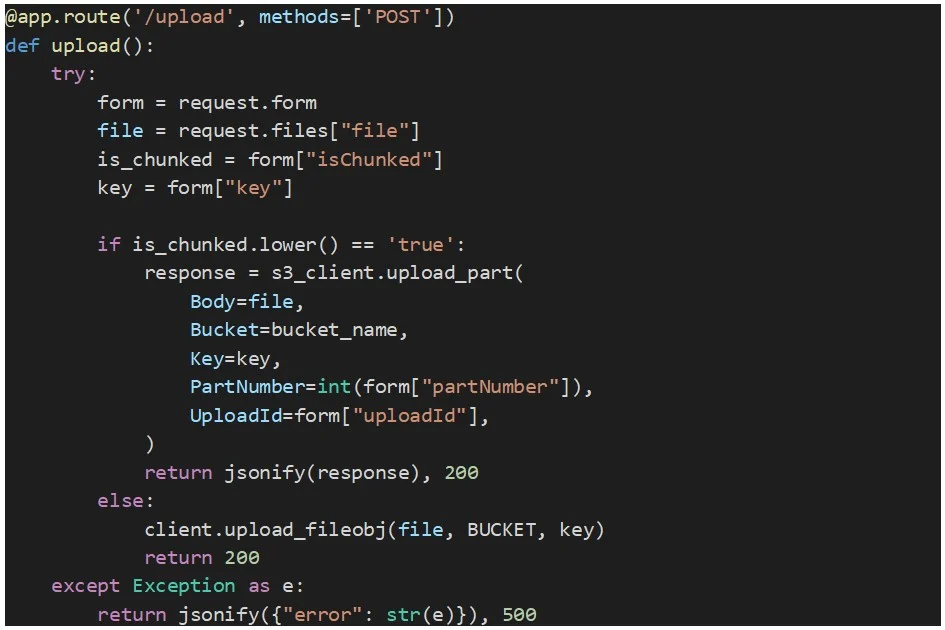
Dieser Endpunkt empfängt eine Datei oder einen Dateiteil als Binärdaten zusammen mit dem S3-Objektschlüssel, der Upload-ID (erhalten von der „create_multipart_upload“-Methode), der Teilenummer (eindeutige Nummer für jeden Teil, beginnend bei 1) und einem Flag, das angibt, ob es sich bei dem Upload um einen Dateiteil oder eine ganze Datei handelt.
Der Teil wird mit der Methode „upload_part“ in S3 hochgeladen. Unten finden Sie den Quellcode für diesen Endpunkt:
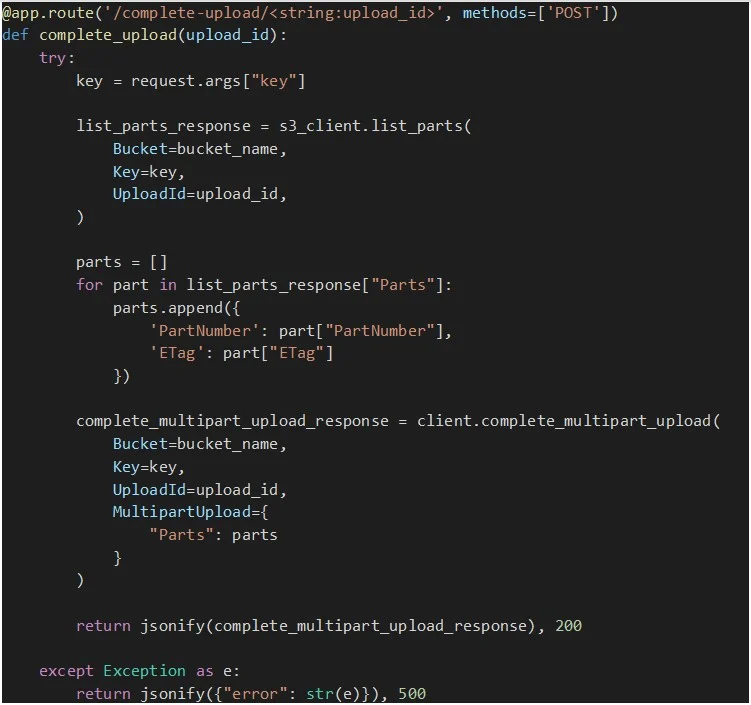
Sobald alle Dateiteile erfolgreich hochgeladen wurden, wird dieser Endpunkt aufgerufen, um den mehrteiligen Upload abzuschließen. Zunächst müssen wir jedoch einen laufenden mehrteiligen Upload und alle erforderlichen Informationen zu den bisher hochgeladenen Teilen haben, wie z. B. den ETag (ein MD5-Hash, der die Daten des Teils darstellt) und die Teilenummern.
Um diese Daten über die Teile zu erhalten, die bereits für einen bestimmten mehrteiligen Upload hochgeladen wurden, rufen wir die Methode „list_parts“ auf, die eine Liste von Wörterbüchern abruft, die jeweils ein hochgeladenes Teil darstellen und Details wie Teilenummer und ETag enthalten.
Sobald wir alle Teileinformationen haben, wird die Methode „complete_multipart_upload“ aufgerufen, damit S3 alle Teile zum endgültigen Objekt zusammenfügt und in unserem Bucket zur Verfügung stellt.
Nachfolgend finden Sie eine Implementierung des Endpunkts:
Zur Implementierung der Web-Front-End-Seite verwenden wir Dropzone.js, eine weit verbreitete Open-Source-JavaScript-Bibliothek, die eine elegante und flexible Möglichkeit bietet, Datei-Uploads mit Drag-and-Drop-Funktionalität zu implementieren. Sie vereinfacht den Prozess der Handhabung von Datei-Uploads durch die Bereitstellung einer sofort einsatzbereiten benutzerfreundlichen Oberfläche und übernimmt verschiedene Aufgaben im Zusammenhang mit Uploads, wie z. B. die Validierung von Dateien, das Chunking großer Dateien und die Unterstützung für das Hochladen mehrerer Dateien.
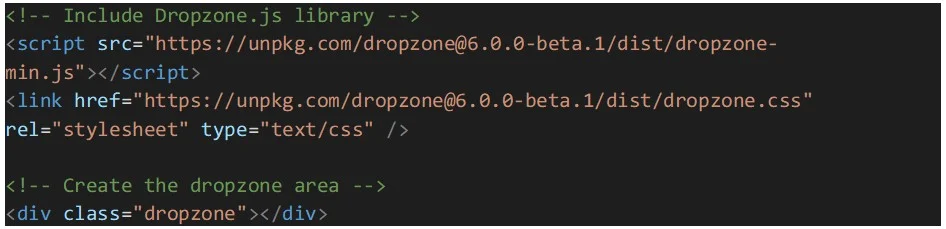
Beginnen wir mit der Einrichtung von Dropzone.js, indem wir sie in die HTML-Datei einfügen. Wir können die Bibliothek entweder herunterladen und lokal darauf verweisen oder einen CDN-Link verwenden. Zusätzlich muss ein HTML-Element erstellt werden, das als Dropzone-Bereich dient, in dem Benutzer Dateien per Drag-and-Drop ablegen können:
Der nächste Schritt ist die Konfiguration von Dropzone.js:
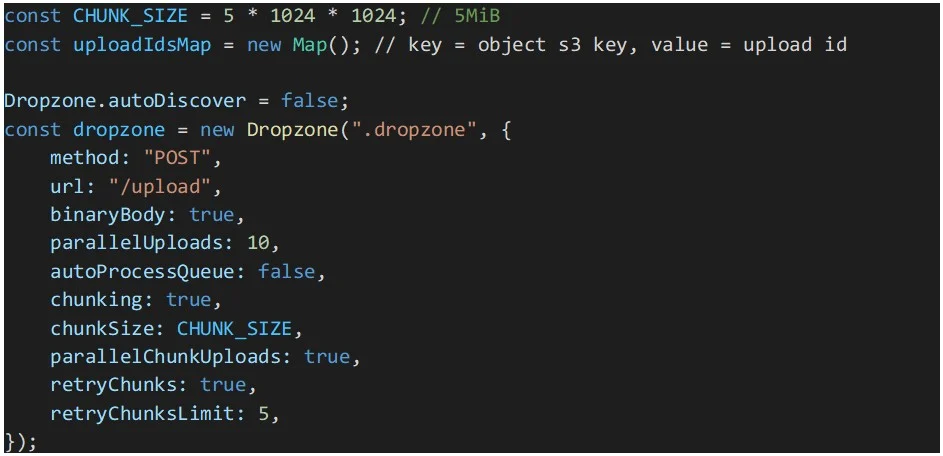
Im obigen Codeausschnitt wird eine Konstante für die Chunk-Größe von Dropzone verwendet, um Dateien in 5-MiB-Teile oder Chunks aufzuteilen. Beachten Sie, dass die Größe in Mebibytes und nicht in Megabytes angegeben wird. Ein Mebibyte ist etwas größer als ein Megabyte und 5 MiB ist die Mindestgröße, die von AWS S3-Mehrfach-Uploads unterstützt wird. Dropzone teilt alle Dateien in Chunks auf, die gleich oder größer als der Wert „chunkSize“ sind.
Um Datei-Uploads zu beschleunigen, ist die Parallelisierung von Teil-Uploads aktiviert. Und um unsere mehrteiligen Uploads widerstandsfähiger zu machen, wurden Wiederholungsversuche für die Teil-Uploads aktiviert, die möglicherweise fehlschlagen.
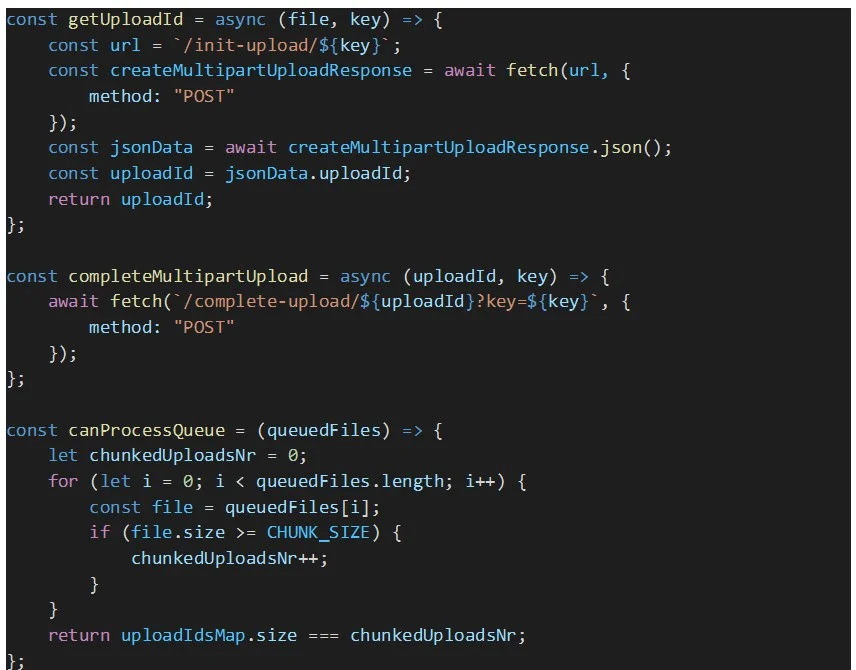
Die automatische Verarbeitung von Dateien in der Warteschlange wurde deaktiviert, da wir sicherstellen müssen, dass alle Dateien in der Warteschlange ihre AWS S3-Multipart-Upload-ID erhalten, bevor Dropzone mit der Verarbeitung der Dateien in der Warteschlange beginnt. Andernfalls besteht das Risiko, dass der Upload einiger Dateiteile aufgrund einer fehlenden Upload-ID fehlschlägt. Diese IDs werden in der Karte „uploadIdsMap“ gespeichert.
Hinweis: Achten Sie darauf, die Initialisierung von Dropzone aufzuschieben, bis die Seite geladen ist. Dies kann z. B. mit einem sofort aufgerufenen Funktionsausdruck erreicht werden.
Da Dropzone bei jeder Upload-Anfrage benutzerdefinierte Parameter senden muss, z. B. die Multipart-Upload-ID und den S3-Schlüssel der hochzuladenden Datei, müssen wir die „params“-Option von Dropzone wie unten dargestellt überschreiben:
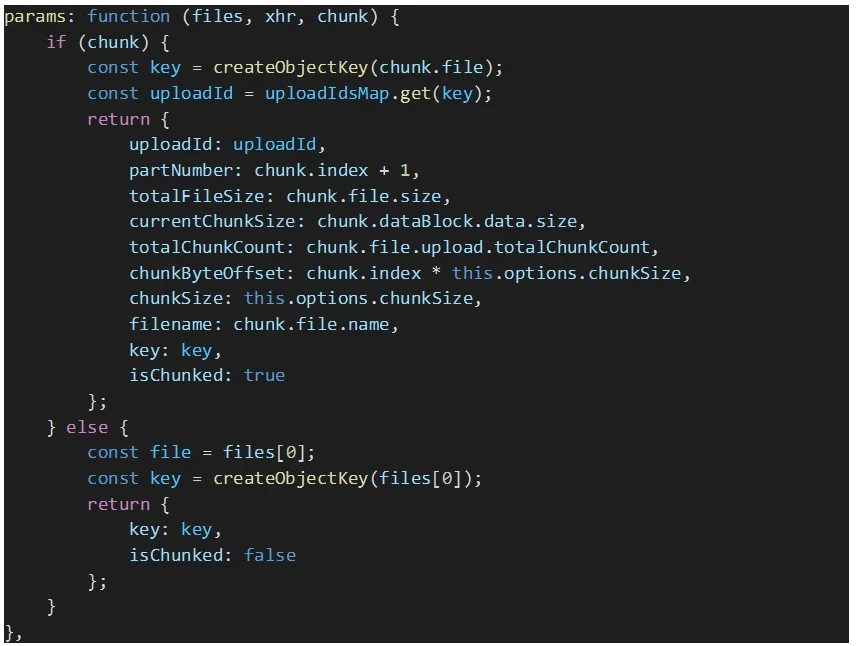
Um den S3-Objektschlüssel für die hochgeladene Datei zu erstellen, wird die folgende Funktion verwendet:

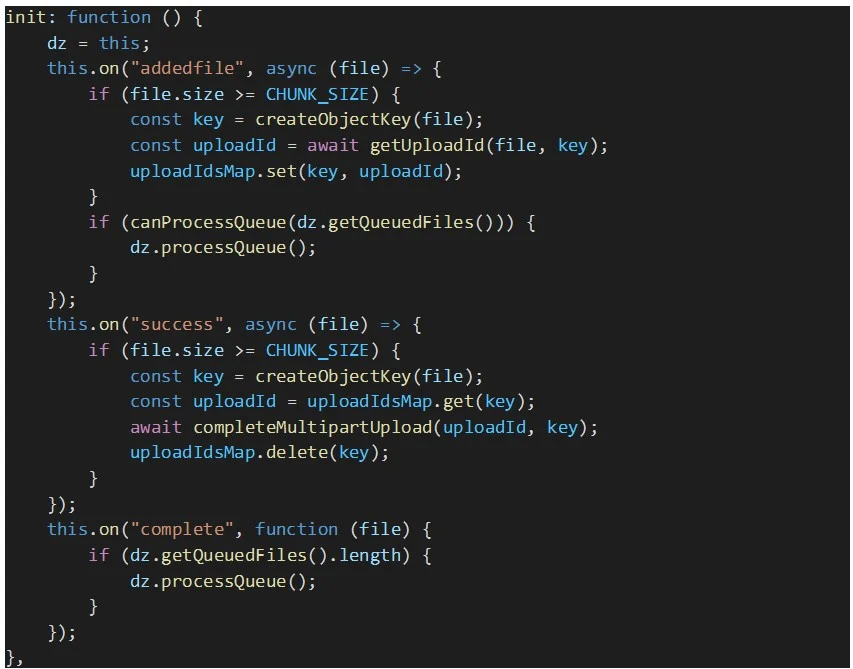
Schließlich müssen wir die folgenden Ereignisse von Dropzone verarbeiten:
Nachfolgend finden Sie die Codeausschnitte, die die oben beschriebenen Ereignisbehandlungsroutinen von Dropzone implementieren, zusammen mit anderen Hilfsfunktionen, die in diesen Behandlungsroutinen verwendet werden.
AWS S3 Multipart Uploads ist eine leistungsstarke Funktion, die die Leistung, Zuverlässigkeit und Flexibilität beim Hochladen großer Objekte in Amazon S3 verbessert. Durch die Aufteilung von Objekten in kleinere Teile können Entwickler parallele Uploads und Wiederaufnahmefunktionen nutzen, was zu schnelleren und zuverlässigeren Uploads führt.
Ob Sie an einer datenintensiven Anwendung, einem Multimedia-Speicher oder einem Content-Delivery-System arbeiten – das Verständnis und die Implementierung von Multipart Uploads kann Ihre S3-Datenverwaltungs-Workflowserheblich verbessern und sie zu einem unverzichtbaren Werkzeug im Arsenal der AWS-Cloud machen.
AWS (Amazon Web Services) S3 Multipart Upload ist eine Funktion, die es ermöglicht, große Objekte (Dateien) in kleineren Teilen oder „Chunks“ auf Amazon Simple Storage Service (S3) hochzuladen und diese dann serverseitig zu einem vollständigen Objekt zusammenzusetzen.
Dieser Prozess bietet mehrere Vorteile gegenüber herkömmlichen einzelnen Uploads:
Um einen mehrteiligen Upload zu starten, müssen wir eine neue mehrteilige Upload-Anfrage mit der S3-API erstellen und dann einzelne Teile des Objekts in separaten API-Aufrufen hochladen, die jeweils durch eine eindeutige Teilenummer identifiziert werden.
Sobald alle Teile hochgeladen sind, ist der mehrteilige Upload abgeschlossen und S3 fügt die Teile zum endgültigen Objekt zusammen. Außerdem können Sie einen mehrteiligen Upload jederzeit abbrechen, um hochgeladene Teile zu bereinigen und Speicherkosten zu sparen.
Mehrteilige Uploads werden häufig verwendet, wenn es sich um Dateien handelt, die in der Regel größer als 100 MB sind, oder wenn während des Upload-Vorgangs instabile Netzwerkbedingungen zu erwarten sind.
In diesem Artikel sollen die Vorteile von AWS S3-Multipart-Uploads, detailliert und praktisch veranschaulicht werden, indem eine Implementierung mit Dropzone.js und dem Python-Framework Flask zusammen mit dem AWS S3 boto3 Python SDK bereitgestellt wird.
Aus Sicherheitsgründen werden die Anfragen an S3 über eine Flask-REST-API weitergeleitet. Beginnen wir mit der Erstellung und Einrichtung der Flask-App:
Als Nächstes erstellen wir drei Flask-Endpunkte für die folgenden Funktionen:
Die unten aufgeführte Endpunktimplementierung startet einen mehrteiligen Upload in den angegebenen S3-Bucket und Objektschlüssel unter Verwendung des Boto3 SDK.
Die Funktion „create_multipart_upload“ wird aufgerufen, um einen neuen mehrteiligen Upload zu erstellen, und die von der API zurückgegebene „UploadId“ ist in der Antwort enthalten.
Dieser Endpunkt empfängt eine Datei oder einen Dateiteil als Binärdaten zusammen mit dem S3-Objektschlüssel, der Upload-ID (erhalten von der „create_multipart_upload“-Methode), der Teilenummer (eindeutige Nummer für jeden Teil, beginnend bei 1) und einem Flag, das angibt, ob es sich bei dem Upload um einen Dateiteil oder eine ganze Datei handelt.
Der Teil wird mit der Methode „upload_part“ in S3 hochgeladen. Unten finden Sie den Quellcode für diesen Endpunkt:
Sobald alle Dateiteile erfolgreich hochgeladen wurden, wird dieser Endpunkt aufgerufen, um den mehrteiligen Upload abzuschließen. Zunächst müssen wir jedoch einen laufenden mehrteiligen Upload und alle erforderlichen Informationen zu den bisher hochgeladenen Teilen haben, wie z. B. den ETag (ein MD5-Hash, der die Daten des Teils darstellt) und die Teilenummern.
Um diese Daten über die Teile zu erhalten, die bereits für einen bestimmten mehrteiligen Upload hochgeladen wurden, rufen wir die Methode „list_parts“ auf, die eine Liste von Wörterbüchern abruft, die jeweils ein hochgeladenes Teil darstellen und Details wie Teilenummer und ETag enthalten.
Sobald wir alle Teileinformationen haben, wird die Methode „complete_multipart_upload“ aufgerufen, damit S3 alle Teile zum endgültigen Objekt zusammenfügt und in unserem Bucket zur Verfügung stellt.
Nachfolgend finden Sie eine Implementierung des Endpunkts:
Zur Implementierung der Web-Front-End-Seite verwenden wir Dropzone.js, eine weit verbreitete Open-Source-JavaScript-Bibliothek, die eine elegante und flexible Möglichkeit bietet, Datei-Uploads mit Drag-and-Drop-Funktionalität zu implementieren. Sie vereinfacht den Prozess der Handhabung von Datei-Uploads durch die Bereitstellung einer sofort einsatzbereiten benutzerfreundlichen Oberfläche und übernimmt verschiedene Aufgaben im Zusammenhang mit Uploads, wie z. B. die Validierung von Dateien, das Chunking großer Dateien und die Unterstützung für das Hochladen mehrerer Dateien.
Beginnen wir mit der Einrichtung von Dropzone.js, indem wir sie in die HTML-Datei einfügen. Wir können die Bibliothek entweder herunterladen und lokal darauf verweisen oder einen CDN-Link verwenden. Zusätzlich muss ein HTML-Element erstellt werden, das als Dropzone-Bereich dient, in dem Benutzer Dateien per Drag-and-Drop ablegen können:
Der nächste Schritt ist die Konfiguration von Dropzone.js:
Im obigen Codeausschnitt wird eine Konstante für die Chunk-Größe von Dropzone verwendet, um Dateien in 5-MiB-Teile oder Chunks aufzuteilen. Beachten Sie, dass die Größe in Mebibytes und nicht in Megabytes angegeben wird. Ein Mebibyte ist etwas größer als ein Megabyte und 5 MiB ist die Mindestgröße, die von AWS S3-Mehrfach-Uploads unterstützt wird. Dropzone teilt alle Dateien in Chunks auf, die gleich oder größer als der Wert „chunkSize“ sind.
Um Datei-Uploads zu beschleunigen, ist die Parallelisierung von Teil-Uploads aktiviert. Und um unsere mehrteiligen Uploads widerstandsfähiger zu machen, wurden Wiederholungsversuche für die Teil-Uploads aktiviert, die möglicherweise fehlschlagen.
Die automatische Verarbeitung von Dateien in der Warteschlange wurde deaktiviert, da wir sicherstellen müssen, dass alle Dateien in der Warteschlange ihre AWS S3-Multipart-Upload-ID erhalten, bevor Dropzone mit der Verarbeitung der Dateien in der Warteschlange beginnt. Andernfalls besteht das Risiko, dass der Upload einiger Dateiteile aufgrund einer fehlenden Upload-ID fehlschlägt. Diese IDs werden in der Karte „uploadIdsMap“ gespeichert.
Hinweis: Achten Sie darauf, die Initialisierung von Dropzone aufzuschieben, bis die Seite geladen ist. Dies kann z. B. mit einem sofort aufgerufenen Funktionsausdruck erreicht werden.
Da Dropzone bei jeder Upload-Anfrage benutzerdefinierte Parameter senden muss, z. B. die Multipart-Upload-ID und den S3-Schlüssel der hochzuladenden Datei, müssen wir die „params“-Option von Dropzone wie unten dargestellt überschreiben:
Um den S3-Objektschlüssel für die hochgeladene Datei zu erstellen, wird die folgende Funktion verwendet:
Schließlich müssen wir die folgenden Ereignisse von Dropzone verarbeiten:
Nachfolgend finden Sie die Codeausschnitte, die die oben beschriebenen Ereignisbehandlungsroutinen von Dropzone implementieren, zusammen mit anderen Hilfsfunktionen, die in diesen Behandlungsroutinen verwendet werden.
AWS S3 Multipart Uploads ist eine leistungsstarke Funktion, die die Leistung, Zuverlässigkeit und Flexibilität beim Hochladen großer Objekte in Amazon S3 verbessert. Durch die Aufteilung von Objekten in kleinere Teile können Entwickler parallele Uploads und Wiederaufnahmefunktionen nutzen, was zu schnelleren und zuverlässigeren Uploads führt.
Ob Sie an einer datenintensiven Anwendung, einem Multimedia-Speicher oder einem Content-Delivery-System arbeiten – das Verständnis und die Implementierung von Multipart Uploads kann Ihre S3-Datenverwaltungs-Workflowserheblich verbessern und sie zu einem unverzichtbaren Werkzeug im Arsenal der AWS-Cloud machen.
